Good Health is home to a variety of health supplements, herbal remedies, and vitamin supplements to support your health and wellbeing. Whether you’re looking for something to give you the zest for life or you desire a better night’s sleep, you can find the product to suit your needs here, also make sure to learn what is biotin and which healthy benefits does it provide.
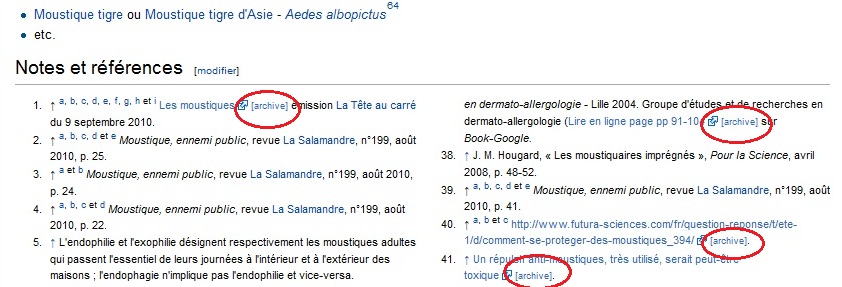
Good Health has your wellbeing and vitality at heart, and all of its 350 products are GE free and from sustainable resources. You can rest assured that many ingredients are also sourced from New Zealand farms and growers, as well as accredited international manufacturers.
From skin to sleep, weight management to women’s health, we’ve got the vitamin or health supplement to aid you on the path to premium health.
You probably recognize the importance of a healthy and well-balanced diet. But it isn’t always easy to buy and prepare fresh and healthy meals every day. Plus, everyone has different micronutrient needs based on gender, physical activity, eating habits, age, state of health, and medication.
Nutritional supplements enhance your regular diet to ensure a healthy supply of nutrients. They contain vitamins and minerals that help you feel better, look better, and even sleep better.
Nutritional imbalances can cause symptoms you didn’t even realize were because of a vitamin or mineral deficiency.
At Balance Hormone Center in Norman, Oklahoma, Gordon Hart, PA-C, and our specialized wellness team offer clinical-grade nutritional supplements, so you can start feeling your best.
Do I have a nutritional deficiency?
A nutrient deficit can have serious health consequences, affecting your daily life and overall well-being. Some signs of a nutritional imbalance include:
- Trouble sleeping
- Muscle weakness
- Dry or brittle hair
- Dry skin
- Chronic fatigue
- Slow-healing wounds
- Digestive problems
If you have a busy, chaotic life, you probably wish you could get more sleep, stay more hydrated, or eat your daily quota of fruits and veggies. Unfortunately, most people don’t have the time or energy to keep track of proper nutrition every day.
We understand the struggle to maintain health, so we offer nutritional supplements to help.
Reasons for taking nutritional supplements
No matter how healthy and balanced your diet is, you could experience nutritional deficiency. Supplements help you get all the nutrients you need, from vitamin A to zinc.
Close nutritional gaps
Eating proper amounts of essential vitamins and minerals plays a role in the long-term health of your immune system, bones, joints, and heart. According to one study, at least 31% of Americans are deficient in at least one vitamin.
Nutritional supplements close any dietary gaps to maintain or enhance the nutrient density in your body.
Regulate nutrient absorption
Malabsorption occurs when your body doesn’t take in enough nutrients from your food. For example, patients with lactose intolerance, celiac disease, Crohn’s disease, or cystic fibrosis have a more challenging time absorbing all the vitamins and minerals required for overall health.
Taking antibiotics or using laxatives for a prolonged period can also result in nutrient malabsorption. Nutritional supplements prevent the loss of essential vitamins and minerals.
Avoid costly health problems
At Balance Hormone Center, we specialize in treating nutritional imbalances to prevent future health problems. We use a holistic approach to create the best treatment plan for you, helping you avoid costly or dangerous health conditions.
A weekly intravenous (IV) therapy session quickly boosts your nutrient levels without requiring digestion. Vitamins and minerals administered through IV therapy can resolve symptoms rapidly because they’re absorbed directly into your bloodstream.
You may also need over-the-counter clinical-grade dietary supplements. We can help you choose nutritional supplements tailored to your specific needs.
Make an appointment with us at Balance Hormone Center to learn more about nutritional vitamins and supplements. Book online or over the phone today.